Big Data & Hadoop Certfied Course in Mohali

Join Best Big Data Training in Mohali
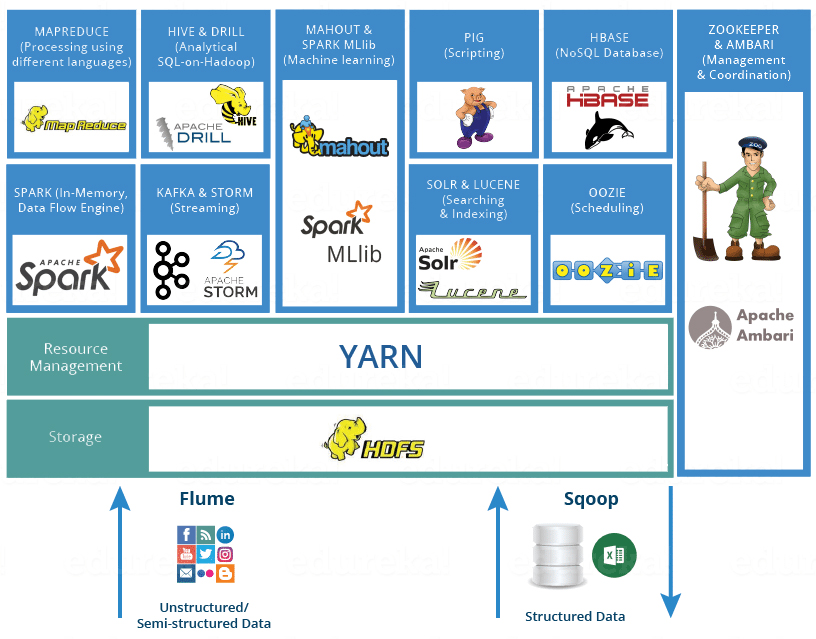
Itronix Solutions provides Best Big Data & Hadoop Training in Mohali as per the current industry standards. Itronix Solutions is one of the most recommended Best Big Data & Hadoop Training Institute in Mohali that offers hands-on practical knowledge/ practical implementation on live case studies and will ensure the job with the help of advanced level Best Big Data & Hadoop Training Courses. At Itronix Solutions Best Big Data & Hadoop Training in Mohali is conducted by specialist working certified corporate professionals having 10+ years of experience in implementing real-time Best Big Data & Hadoop projects and case studies
Big Data and Hadoop Course Curriculum
Module 1: Introduction to Big Data
- Introduction to Big Data and Hadoop
- Big Data Analytics
- What is Big Data?
- Four v’s of Big Data
- Rise of Big Data
- Compare Hadoop vs traditional systems
- Hadoop Master-Slave Architecture
- Understanding HDFS Architecture
- NameNode, DataNode, Secondary Node
- Learn about JobTracker, TaskTracker, Resource Manager, Node Manager
Module 2: HDFS and MapReduce Architecture
- Hadoop Architecture Distributed Storage (HDFS) and Yarn
- What is HDFS
- Need for HDFS
- Regular File System vs HDFS
- Characteristics of HDFS
- HDFS Architecture and Components
- High Availability Cluster Implementations
- HDFS Component File System Namespace
- Data Block Split
- Data Replication Topology
- HDFS Command Line
- Yarn Introduction
- Yarn Use Case
- Yarn and Its Architecture
- Resource Manager
- How Resource Manager Operates
- Application Master
- How Yarn Runs an Application
- Tools for Yarn Developers
- Core components of Hadoop
- Understanding Hadoop Master-Slave Architecture
- Learn about NameNode, DataNode, Secondary Node
- Understanding HDFS Architecture
- Anatomy of Read and Write data on HDFS
- MapReduce Architecture Flow
- JobTracker and TaskTracker
- Resource Manager and Node Manager
Module 3: Hadoop Configuration
- Hadoop Modes
- Hadoop Terminal Commands
- Cluster Configuration
- Web Ports
- Hadoop Configuration Files
- Reporting, Recovery
- MapReduce in Action
Module 4: Understanding Hadoop MapReduce Framework
- Overview of the MapReduce Framework
- Use cases of MapReduce
- MapReduce Architecture
- Anatomy of MapReduce Program
- Mapper/Reducer Class, Driver code
- Understand Combiner and Partitioner
Module 5: Advance MapReduce – Part 1
- Write your own Partitioner
- Writing Map and Reduce in Python
- Map side/Reduce side Join
- Distributed Join
- Distributed Cache
- Counters
- Joining Multiple datasets in MapReduce
Module 6: Advance MapReduce – Part 2
- MapReduce internals
- Understanding Input Format
- Custom Input Format
- Using Writable and Comparable
- Understanding Output Format
- Sequence Files
- JUnit and MRUnit Testing Frameworks
Module 7: Apache Pig
- Apache Pig Introduction
- Apache Pig Architecture
- Apache Pig Installation
- Apache Pig Execution
- Apache Pig Grunt Shell
- Apache Pig – Reading Data
- Apache Pig – Storing Data
- Apache Pig – Diagnostic Operator
- Apache Pig – Describe Operator
- Apache Pig – Explain Operator
- Apache Pig – Illustrate Operator
- Apache Pig – Group Operator
- Apache Pig – Cogroup Operator
- Apache Pig – Join Operator
- Apache Pig – Cross Operator
- Apache Pig – Union Operator
- Apache Pig – Split Operator
- Apache Pig – Filter Operator
- Apache Pig – Distinct Operator
- Apache Pig – Foreach Operator
- Apache Pig – Order By
- Apache Pig – Limit Operator
- Apache Pig – Eval Functions
- Apache Pig – Bag & Tuple Functions
- Apache Pig – String Functions
- Apache Pig – date-time Functions
- Apache Pig – Math Functions
Module 8: Apache Hive and HiveQL
- Hive – Introduction
- Hive – Installation
- Hive – Data Types
- Hive – Create Database
- Hive – Drop Database
- Hive – Create Table
- Hive – Alter Table
- Hive – Drop Table
- Hive – Partitioning
- Hive – Built-In Operators
- Hive – Built-In Functions
- Hive – Views And Indexes
- Difference between Hive and RDBMS
Module 9: Advance HiveQL
- Multi-Table Inserts
- Joins
- Grouping Sets, Cubes, Rollups
- Custom Map and Reduce scripts
- Hive SerDe
- Hive UDF
- Hive UDAF
- Hive Partitioning
- Dynamic Partitioning in Hive
- Hive Bucketing
- Hive Partitioning and Bucketing together
- Hive Data Sampling
Module 10: Apache Flume, Sqoop, Oozie
- Sqoop – How Sqoop works
- Sqoop Architecture
- Flume – How it works
- Flume Complex Flow – Multiplexing
- Oozie – Simple/Complex Flow
- Oozie Service/ Scheduler
- Use Cases – Time and Data triggers
Module 11 NoSQL Databases
- CAP theorem
- RDBMS vs NoSQL
- Key Value stores: Memcached, Riak
- Key Value stores: Redis, Dynamo DB
- Column Family: Cassandra, HBase
- Graph Store: Neo4J
- Document Store: MongoDB, CouchDB
Module 12 Apache HBase
- When/Why to use HBase
- HBase Architecture/Storage
- HBase Data Model
- HBase Families/ Column Families
- HBase Master
- HBase vs RDBMS
- Access HBase Data
- HBase – Overview
- HBase – Architecture
- HBase – Installation
- HBase – Shell
- HBase – General Commands
- HBase – Admin API
- HBase – Create Table
- HBase – Listing Table
- HBase – Disabling a Table
- HBase – Enabling a Table
- HBase – Describe & Alter
- HBase – Exists
- HBase – Drop a Table
- HBase – Shutting Down
- HBase – Client API
- HBase – Create Data
- HBase – Update Data
- HBase – Read Data
- HBase – Delete Data
- HBase – Scan
- HBase – Count & Truncate
- HBase – Security
Module 13 Apache Zookeeper
- What is Zookeeper
- Zookeeper Data Model
- ZNokde Types
- Sequential ZNodes
- Installing and Configuring
- Running Zookeeper
- Zookeeper use cases
Module 14 Hadoop 2.0, YARN, MRv2
- Hadoop 1.0 Limitations
- MapReduce Limitations
- HDFS 2: Architecture
- HDFS 2: High availability
- HDFS 2: Federation
- YARN Architecture
- Classic vs YARN
- YARN multitenancy
- YARN Capacity Scheduler
Module 15: Basics of Functional Programming and Scala
- Scala – Overview
- Scala – Environment Setup
- Scala – Basic Syntax
- Scala – Data Types
- Scala – Variables
- Scala – Classes & Objects
- Scala – Access Modifiers
- Scala – Operators
- Scala – IF ELSE
- Scala – Loop Statements
- Scala – Functions
- Scala – Closures
- Scala – Strings
- Scala – Arrays
- Scala – Collections
- Scala – Traits
- Scala – Pattern Matching
- Scala – Regular Expressions
- Scala – Exception Handling
- Scala – Extractors
- Scala – Files I/O
Module 16: Apache Spark Next-Generation Big Data Framework
- History of Spark
- Limitations of Mapreduce in Hadoop
- Introduction to Apache Spark
- Components of Spark
- Application of In-memory Processing
- Hadoop Ecosystem vs Spark
- Advantages of Spark
- Spark Architecture
- Spark Cluster in Real World
- Demo: Running a Scala Programs in Spark Shell
- Demo: Setting Up Execution Environment in Ide
- Demo: Spark Web UI
- Apache Spark – Core Programming
- Apache Spark – Deployment
- Advanced Spark Programming
Module 17: Spark MLLib Modelling BigData with Spark
- Spark Mllib Modeling Big Data With Spark
- Role of Data Scientist and Data Analyst in Big Data
- Analytics in Spark
- Machine Learning
- Supervised Learning
- Demo: Classification of Linear Svm
- Demo: Linear Regression With Real World Case Studies
- Unsupervised Learning
- Demo: Unsupervised Clustering K-means
- Reinforcement Learning
- Semi-supervised Learning
- Overview of Mllib
Top Reasons to join Itronix Solutions for Master A-Z Big Data Hadoop Course in Mohali:
- We provide Big Data and Hadoop Video Tutorials of the classroom sessions, so in case if the candidate missed any class he/she can learn from those video tutorials by Er Karan Arora
- All our training programs are based on live case studies and industry oriented projects.
- Our training curriculum is approved by our data scientists and placement partners.
- Training/Coaching are going to be conducted on daily & weekly basis and conjointly. We will customize the training schedule as per the candidate necessities.
- We have one of the biggest team of certified expertise with 8+ years of real industry experience.
- Training will be conducted by our Founder and Data Scientists.
- Our Labs are terribly well-equipped with upgraded version of hardware and software.
- Our classrooms are fully geared up with projectors, Smart Labs, Smart Tablets & Wi-Fi access.
- We provide free personality development classes which includes Fluency, Group Discussions, Job interviews Preparation & Presentation skills.
- You will get study material in form of E-Book’s, Jupyter Notebooks and 1500 Interview Questions.
- Worldwide Recognized Course Completion Certificate by IBM, once you’ve completed the course.
- Flexible Payment options such as Paytm, Cheques, Google Pay, Cash, Credit Card, UPI, Debit Card and Net Banking.
- Big Data & Hadoop training in Mohali is designed according to current IT Standards.
- We offer the best Big Data & Hadoop training and placement in Mohali with well-defined training modules & curriculum
- 24×7 lab facility. Students/Professionals are free to access the labs, Desktops for as per their own preferred or suitable timings.
Itronix Solutions Placement Assistance for Big Data Training | Course in Mohali
Being one of the top Big Data and Hadoop Training Company Mohali and a Certified Microsoft Authorized Education Partner, Cisco Partners, Intel Technology Provider, Google Certified Professionals & IBM Certified. Itronix Solutions deals with 100% Job Placements for Eligible Students after successful completion of the course.
- Itronix Solutions helps to keep you updated with latest trends and technologies in Big Data and Hadoop.
- Itronix Solutions helps in updating your resume according to the job or company requirement
- Itronix Solutions helps in providing placement assistance in top IT FIRMS. Many of our alumni are working in ValueCoders, ArStudiouz, PixelCrayons,Prolitus, Space-O Technologies, Technostacks Infotech Pvt. Ltd, Focaloid Technologies,RIT Solution, iPraxa Inc, Webtunix AI TCS, Amazon, Facebook, Sasken, CrossML, Infosys, Google, Uber and Wipro